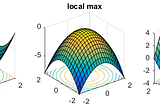
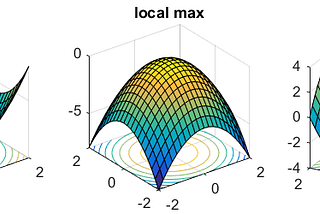
PinnedDevanshinGeek CultureUnderstanding Google’s GPT Killer- The Pathways ArchitectureThe reason why their model Bard will be much more than a language modelFeb 18, 20237Feb 18, 20237
PinnedDevanshinGeek CultureImprove Neural Networks by using Complex NumbersCan Complex Functions be the next breakthrough in Computer Vision?Nov 17, 20225Nov 17, 20225
PinnedDevanshinGeek CultureHow Amazon makes Machine Learning TrustworthyWith all the discussion around Bias in ChatGPT and Machine Learning, these techniques might be very helpfulDec 12, 20221Dec 12, 20221
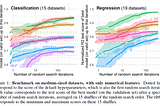
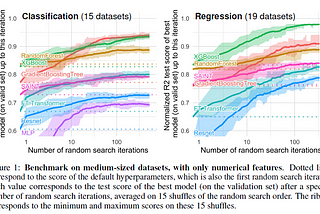
PinnedDevanshinGeek CultureWhy Tree-Based Models Beat Deep Learning on Tabular DataA much-needed reality check for AI Researchers and Engineers caught up in the hype around Deep LearningAug 27, 20225Aug 27, 20225
PinnedDevanshinGeek CultureHow to learn Machine Learning in 2022A step by step guide to getting into machine learningJan 20, 20223Jan 20, 20223
DevanshInteresting Content in AI, Software, Business, and Tech- 07/24/2024Content to help you keep up with Machine Learning, Deep Learning, Data Science, Software Engineering, Finance, Business, and more1d ago1d ago
DevanshHow to Detect Deepfakes with AI Part 2: A Complete PipelineThe end-end foundation for the next generation of Deepfake Detection6d ago6d ago
DevanshHow to Detect Deepfakes with Part 1: Is Generalizable Deepfake Detection Possible?Leveraging the properties of AI Generated Content to detect Deepfakes with Machine LearningJul 19Jul 19
DevanshHow SWE-Agent uses large language models and Agent-Computer Interfaces to improve software…ACI has been achieved internally: How to solve complex software engineering tasks with AI-AgentsJul 16Jul 16
DevanshInteresting Content in AI, Software, Business, and Tech- 07/10/2024Content to help you keep up with Machine Learning, Deep Learning, Data Science, Software Engineering, Finance, Business, and moreJul 111Jul 111