A new, better way to build Neural Networks for Machine Learning
How taking inspiration from the design of our brains can lead to AI with better performance, for cheaper.
As promised here is part 2 for one of the most interesting ideas I have come across in recent times. In case you missed it, make sure you catch part 1 of this series- A Neuroscientists view into Improving Neural Networks- where we talked about the biological basis of bilaterality and how the asymmetric nature of our brains leads to greater performance. In this piece, I will be going over some AI Research that shows great promise regarding this idea. If one of you is looking for your next research paper/project- this might be a great place to look. For whatever my opinion is worth- I believe that solving bilaterality in neural networks will be a true game-changer in the AI space. If any of you want to work on this, you know how to reach me.
PS- I am in currently Denver, Colorado. If any of you would like to meet, please let me know. Always happy to see more people and hear what y’all are up to.
Why Bilaterality is going to shake things up
Before I start breaking down the research, I want to take a second to speak about by I’m making such a big deal about bilaterality. Sure, it might work for biological systems, but what do we hope to attain by implementing a similar idea for our ANNs?
To answer this question let’s take a step back and look into how impactful the architecture of a neural network can be to the learning outcomes. Put plainly, every model/architecture decision imposes a certain inductive bias onto our system. By choosing to implement a certain activation function, model configuration, etc- you implicitly choose to prioritize one facet of your data/domain over another. So intuitively, it should make sense that diverse architectural setups will lead to different outcomes.
I could end this section here- but where would the fun in that be? I’ve had to read quite a few papers, and if I had to go through it, you do too ❤. So let’s go over the research that demonstrates architectural decisions and how they influence the model’s internal representation of the data. Let’s start fairly small- when it comes to vision transformers vs CNNs, we see that their different operations lead to objectively different representations of input data. The attention mechanism allows Transformers to keep a “global view of the image” allowing them to extract features very different from ConvNets. Remember, CNNs use kernels to extract features, which restricts means that they find the local features. Attention allows Transformers to bypass this.
Analyzing the internal representation structure of ViTs and CNNs on image classification benchmarks, we find striking differences between the two architectures, such as ViT having more uniform representations across all layers. We explore how these differences arise, finding crucial roles played by self-attention, which enables early aggregation of global information, and ViT residual connections, which strongly propagate features from lower to higher layers.
The above quote is taken from the very interesting, Do Vision Transformers See Like Convolutional Neural Networks? It’s interesting enough that I will do a breakdown of this paper later. The important aspect is the following quote, also from the paper.
…demonstrating that access to more global information also leads to quantitatively different features than computed by the local receptive fields in the lower layers of the ResNet
This extends beyond image tasks. A while back, we tried to answer whether Transformers are effective for Time Series Forecasting tasks (lol no). One of the pitfalls of the transformer architecture was their attention mechanism, which introduced permutational invariance in data ordering(not good for TSF).
More importantly, the main working power of the Transformer architecture is from its multi-head self-attention mechanism, which has a remarkable capability of extracting semantic correlations between paired elements in a long sequence (e.g., words in texts or 2D patches in images), and this procedure is permutation-invariant, i.e., regardless of the order. However, for time series analysis, we are mainly interested in modeling the temporal dynamics among a continuous set of points, wherein the order itself often plays the most crucial role.
To those of you that are feeling particularly masochistic, the paper On the Symmetries of Deep Learning Models and their Internal Representations is a great read when it comes to this concept. The Math is psychotic, but the takeaway is relatively straightforward-
Our work suggests that the symmetries of a network are propagated into the symmetries in that network’s representation of data
Hopefully, this should be enough to convince you that architectures can directly influence how the model perceives data. Thus a powerful idea like Bilaterality is worth exploring. By integrating somewhat complimentary style networks into the same network- we might be able to create an architecture that exceeds the limitations of any one kind of structure.
With all that out of the way, let’s now talk about the star of the show- the bilaterality paper and how we can extend it.
One takeaway from reading Ray Kurzweil’s How to Create a Mind, which I’ve been meaning to reread, was the role of statistics in AI. if each successive result overwrites past results, I can imagine how biased conclusions might accumulate over generations. Applying a bilateral architecture to preserve weights of prior knowledge seems like a good hedge.
- A comment on Part 1 of this piece. Shoutout to Daniel Kurland for this great share.
Join 35K+ tech leaders and get insights on the most important ideas in AI straight to your inbox through my free newsletter- AI Made Simple
How to Apply Bilaterality to Neural Networks
The authors of Deep learning in a bilateral brain with hemispheric specialization did some great work in implementing bilaterality into a neural network. Let’s take a look at their approach and results.
The first thing to understand with a paper like this is their setup. The architecture presented is based on the ResNet-9 model, picked for its good performance on classification and simplicity. To simulate the two hemispheres, we use two different ResNet models (shocking I know). To conduct our experiments we compare the following models (the first is the bilateral model, the rest are baselines)-
- Bilaterality with Specialization- We train the models with different objectives, “the left hemisphere was trained on specific classes and the right hemisphere on general classes”. What does this mean? A general class would be: sea creature while a specific class would be: penguin, seal, shark etc. This is similar to our brains, where the right hemisphere models generalities and the left hemisphere is more specific.
- Bilaterality w/o specialization- “To better understand the role of specialization, we compared the bilateral model to an equivalent network without specialization. We trained the entire network (two hemispheres and heads) without first explicitly inducing specialization in the individual hemispheres.”
- Unicameral network- The bilaterality allows the models to have more computational resources. To account for this, the authors also used two bigger single models with 2 heads for the general and specific classes. More specifically, they used a “predefined 18-layered and 34-layered ResNet architectures. The 18-layered network has approximately the same number of trainable parameters as the bilateral network, and the 34-layered network approximately double.”
- Ensemble Models- As you may be aware, ensemble models are a cheat code to performance in Machine Learning. And this bilateral model is a kind of ensemble. So it is important to also compare against other ensembles, to have a clearer picture of the impact of specialization vs other factors. To understand the differences between differential specialization and conventional ensembling, we compared to two different models, one was a 2-model ensemble and one was a 5-model ensemble. In order to construct the ensembles, we used a common approach where we trained 10 unicameral ResNet-9 models, and selected the top-k (k was 2 and 5 respectively). The output of the ensemble in training and inference was the mean output from the models.
These models had to go against each other to determine the king of the hill. To those of you who like visuals, the general architecture can be seen below.

I like their approach to simulating specialization b/c it’s fairly simple and elegant. A future extension might be to use differing architectures, one with denser localized connections and another with more broad connections (probably using skip connections). To be truly changing- we’d need to tweak the unidirectionality of Gradient Descent, toward a protocol that adjusts weights in multiple directions. This is not an easy feat, but it would be a great avenue for future exploration.
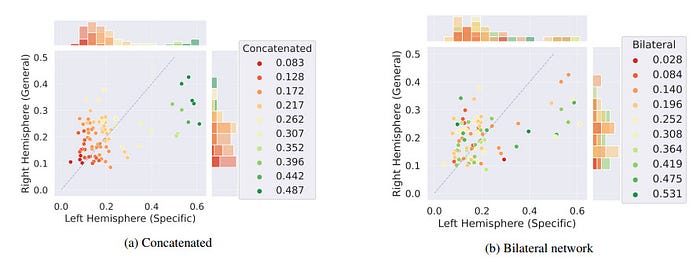
To see the differences in the features extracted from the two specialized models, the authors use two techniques. Firstly, they utilize Gradient camera (Grad-Cam) visualization. We know that the bilateral network and individual hemispheres utilize encoded features from the convolutional layers to predict a class label. To understand how the extracted features contribute to classification, we visualized the gradient flow averaged over convolutional layers while the model predicted a class, using the Grad-Cam library. The gradient heatmap highlights the region of focus for both hemispheres and the overall network (average over both heads). You can see the grad-cam visualizations below.

This is complemented by calculating the cosine similarity scores on the features of images of the same labels. They are expected to have similar features, so measuring the feature similarity at different parts of the network should be revealing. Here is the visualization of the features-
With this setup out of the way, let’s get into the main course. How well does this architecture do against the competitors? This is where things get exciting.
The Grad-Cam images reveal that the left hemisphere extracts more localized features than the right. Different learning objectives enable them to capture different aspects of the environment. Collectively the set of features is greater than one network with one objective. Interestingly, even though the left is explicitly trained on specific class labels, the features that it extracts are helpful for general classes. The inverse is true of the right…
In summary, specialization creates a higher diversity of features. The network heads implement a type of weighted attention to left and right hemispheres selectively in a task dependent manner, improving overall class prediction.
- Why does a bicameral architecture help?
Does Specialization and Bilaterality actually improve performance in Neural Networks?
Simply put- yes. Take a look at the comparison of the Specialized architecture against the competitors. Make sure you keep your hormones in check because these results are lookin’ real pretty-
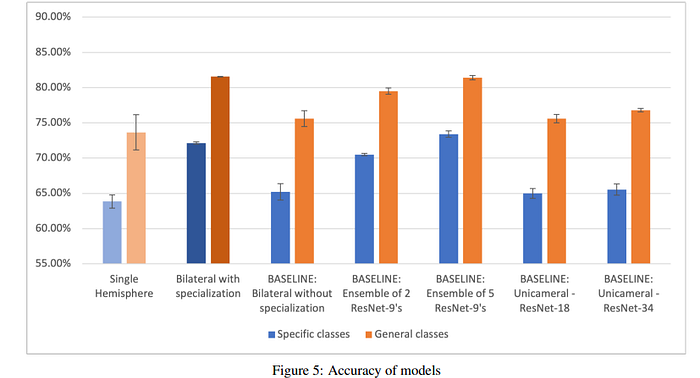
The only competitor that has a comparable performance is the 5-model ensemble- but that comes with a much higher cost.

I would have loved to see how this scales into related tasks like Adversarial learning and detection. Perhaps that will be part of a follow-up paper. Given these results, I’d say we have a fairly strong proof of concept.
To finish up, let’s talk about some ways that this idea can be extended.
Bilaterality for the Future
As mentioned earlier, one of the most promising avenues for future exploration would be creating a more nuanced weight update mechanism, mirroring the more complex ways our neurons and connections fire together. The authors also had several excellent suggestions (based in neuro-science)- “replicating recurrent connectivity, more complex biologically inspired interactions between the hemispheres, mimicking known substrate differences between the hemispheres such as topological differences, resource allocation (see Fig. 1) and experiments on inducing specialization without supervision.”

The authors also mentioned how this specialization could be leveraged to develop physical robots, since it may be tied to motor skills. The right hemisphere could be a generalist that can perform unfamiliar tasks as a beginner, while the left becomes an expert over time. The agent would be able to adopt new tasks, without being inept at them. Currently, the field of Continual RL does not focus on avoiding poor performance, but rather maximizing the best performance. In real-life scenarios however, an agent must avoid death and serious injury to themselves and those around them (also relevant for physical robots and virtual artificial agents).
Lastly, it would be fascinating to see bilateralism integrated into more architectures, to see how well this idea extends to different challenges and domains.
If any of you would like to work on this topic, feel free to reach out to me. As always, if you’re looking for AI Consultancy, Software Engineering implementation, or more- my company, SVAM, helps clients in many ways- application development, strategy consulting, and staffing. Feel free to reach out and share your needs, and we can work something out.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. If you like my writing, I would really appreciate an anonymous testimonial. You can drop it here. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow.

Save the time, energy, and money you would burn by going through all those videos, courses, products, and ‘coaches’ and easily find all your needs met in one place at ‘Tech Made Simple’! Stay ahead of the curve in AI, software engineering, and the tech industry with expert insights, tips, and resources. 20% off for new subscribers by clicking this link. Subscribe now and simplify your tech journey!
Using this discount will drop the prices-
800 INR (10 USD) → 640 INR (8 USD) per Month
8000 INR (100 USD) → 6400INR (80 USD) per year (533 INR /month)
Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819
