Interesting Content in AI, Software, Business, and Tech- 6/29/2023
Another week, another set of updates that you should keep in mind.
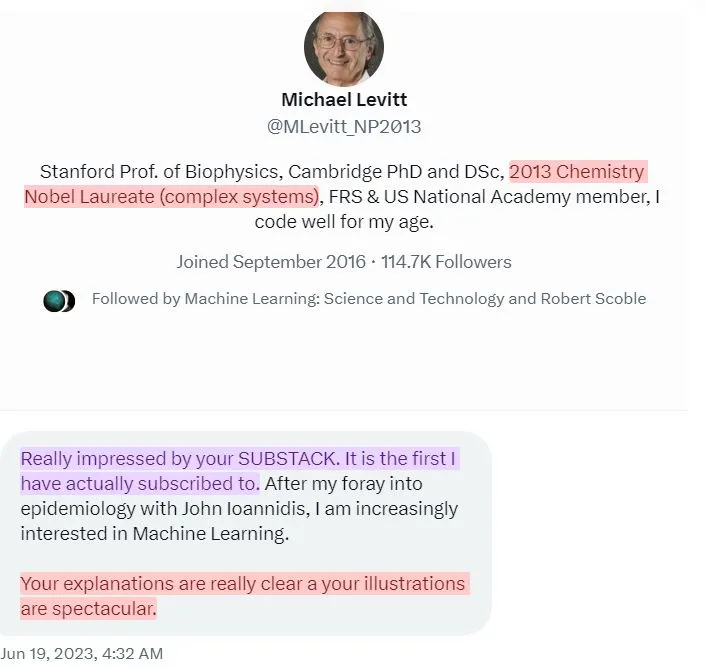
Before we begin, major update. Michael Levitt, a Nobel Prize Winner, reached out to me and told me that he likes my writing. This is a huge honor, and I’m truly grateful to all of you for the reception. Without your kind words, I would have never gotten this far. Made a post about this on LinkedIn over here.
A lot of people reach out to me for reading recommendations. I figured I’d start sharing whatever AI Papers/Publications, interesting books, videos, etc I came across each week. Some will be technical, others not really. I will add whatever content I found really informative (and I remembered throughout the week). These won’t always be the most recent publications- just the ones I’m paying attention to this week. Without further ado, here are interesting readings/viewings for 6/29/2023. If you missed last week’s readings, you can find it here.
Join 35K+ tech leaders and get insights on the most important ideas in AI straight to your inbox through my free newsletter- AI Made Simple
AI Papers/Writeups
Learning Nation-State Censorship with Genetic Algorithms
An interesting slide deck on the use of evolutionary algorithms in getting around government censorship. I did a breakdown of how you can get around government firewalls using AI by going over the parent Project- Project Geneva over here.
Eliminating Bias in AI/ML
An interesting argument about how useful AI is inherently biased and that dealing with AI. Here was a particularly insightful 2 paragraphs-
This is where our AI is merely holding up a mirror to a couple of things. For example, in hiring, it highlights the value you put on certain terms, roles, education, etc. In fact, evidence from Amazon’s recruiting tool shows that it downgraded terms like ‘woman.’ But was this a biased AI/ML or was this reflective of an uncomfortable recognition that the measures of success at Amazon, as opposed to their stated intention, are based on traditional male-dominated attributes? When provided the data on patterns of hiring, the algorithm merely noted that hiring managers routinely downgraded resumes by those who could be coded as ‘woman’. The algorithm didn’t choose to downgrade the term itself, it merely identified an attribute that captured the general trend of hiring.
This was exactly what James Damore attempted to highlight in his infamous 2017 ‘Google Memo’ where his observation was that Google was designed by and for male software engineers and went on to proffer that women might not want to code under those measures of success. Instead of looking at the organization, Damore was pilloried but if we don’t challenge those underlying assumptions about what is valued and we train our AI/ML on those values, we will weight the algorithms toward that bias. Fundamentally, when an algorithm picks up the patterns of ‘success’ based on historic precedent, that isn’t bias in the algorithm, that’s a mirror toward the bias in the organization itself.
Exploring the MIT Mathematics and EECS Curriculum Using Large Language Models
Sarah J. Zhang, Samuel Florin, Ariel N. Lee, Eamon Niknafs, Andrei Marginean, Annie Wang, Keith Tyser, Zad Chin, Yann Hicke, Nikhil Singh, Madeleine Udell, Yoon Kim, Tonio Buonassisi, Armando Solar-Lezama, Iddo Drori
We curate a comprehensive dataset of 4,550 questions and solutions from problem sets, midterm exams, and final exams across all MIT Mathematics and Electrical Engineering and Computer Science (EECS) courses required for obtaining a degree. We evaluate the ability of large language models to fulfill the graduation requirements for any MIT major in Mathematics and EECS. Our results demonstrate that GPT-3.5 successfully solves a third of the entire MIT curriculum, while GPT-4, with prompt engineering, achieves a perfect solve rate on a test set excluding questions based on images. We fine-tune an open-source large language model on this dataset. We employ GPT-4 to automatically grade model responses, providing a detailed performance breakdown by course, question, and answer type. By embedding questions in a low-dimensional space, we explore the relationships between questions, topics, and classes and discover which questions and classes are required for solving other questions and classes through few-shot learning. Our analysis offers valuable insights into course prerequisites and curriculum design, highlighting language models’ potential for learning and improving Mathematics and EECS education.
SqueezeLLM: Dense-and-Sparse Quantization
Link over here
Sehoon Kim, Coleman Hooper, Amir Gholami, Zhen Dong, Xiuyu Li, Sheng Shen, Michael W. Mahoney, Kurt Keutzer
Generative Large Language Models (LLMs) have demonstrated remarkable results for a wide range of tasks. However, deploying these models for inference has been a significant challenge due to their unprecedented resource requirements. This has forced existing deployment frameworks to use multi-GPU inference pipelines, which are often complex and costly, or to use smaller and less performant models. In this work, we demonstrate that the main bottleneck for generative inference with LLMs is memory bandwidth, rather than compute, specifically for single batch inference. While quantization has emerged as a promising solution by representing model weights with reduced precision, previous efforts have often resulted in notable performance degradation. To address this, we introduce SqueezeLLM, a post-training quantization framework that not only enables lossless compression to ultra-low precisions of up to 3-bit, but also achieves higher quantization performance under the same memory constraint. Our framework incorporates two novel ideas: (i) sensitivity-based non-uniform quantization, which searches for the optimal bit precision assignment based on second-order information; and (ii) the Dense-and-Sparse decomposition that stores outliers and sensitive weight values in an efficient sparse format. When applied to the LLaMA models, our 3-bit quantization significantly reduces the perplexity gap from the FP16 baseline by up to 2.1x as compared to the state-of-the-art methods with the same memory requirement. Furthermore, when deployed on an A6000 GPU, our quantized models achieve up to 2.3x speedup compared to the baseline. Our code is open-sourced and available online.
Error Feedback Can Accurately Compress Preconditioners
Ionut-Vlad Modoranu, Aleksei Kalinov, Eldar Kurtic, Dan Alistarh
Leveraging second-order information at the scale of deep networks is one of the main lines of approach for improving the performance of current optimizers for deep learning. Yet, existing approaches for accurate full-matrix preconditioning, such as Full-Matrix Adagrad (GGT) or Matrix-Free Approximate Curvature (M-FAC) suffer from massive storage costs when applied even to medium-scale models, as they must store a sliding window of gradients, whose memory requirements are multiplicative in the model dimension. In this paper, we address this issue via an efficient and simple-to-implement error-feedback technique that can be applied to compress preconditioners by up to two orders of magnitude in practice, without loss of convergence. Specifically, our approach compresses the gradient information via sparsification or low-rank compression \emph{before} it is fed into the preconditioner, feeding the compression error back into future iterations. Extensive experiments on deep neural networks for vision show that this approach can compress full-matrix preconditioners by up to two orders of magnitude without impact on accuracy, effectively removing the memory overhead of full-matrix preconditioning for implementations of full-matrix Adagrad (GGT) and natural gradient (M-FAC). Our code is available at this https URL.
Scaling Spherical CNNs
Carlos Esteves, Jean-Jacques Slotine, Ameesh Makadia
Spherical CNNs generalize CNNs to functions on the sphere, by using spherical convolutions as the main linear operation. The most accurate and efficient way to compute spherical convolutions is in the spectral domain (via the convolution theorem), which is still costlier than the usual planar convolutions. For this reason, applications of spherical CNNs have so far been limited to small problems that can be approached with low model capacity. In this work, we show how spherical CNNs can be scaled for much larger problems. To achieve this, we make critical improvements including novel variants of common model components, an implementation of core operations to exploit hardware accelerator characteristics, and application-specific input representations that exploit the properties of our model. Experiments show our larger spherical CNNs reach state-of-the-art on several targets of the QM9 molecular benchmark, which was previously dominated by equivariant graph neural networks, and achieve competitive performance on multiple weather forecasting tasks. Our code is available at this https URL.
Reader Spotlight- Misha Herscu (Kflow)
K Flow is building a platform for bundled managed open source AI infrastructure. With K Flow, you can piece together best-in-class open source components of an end-to-end AI infrastructure stack that’s fit for your specific needs and use case. Within AI infrastructure, K Flow is focusing on Generative AI / LLM technologies, and is currently working with design partners to provide custom LLM fine-tuning and serving platforms as a far faster and lower cost alternative route to a production-ready system.
K Flow is led by Misha Herscu and Skyler Thomas. You can reach out to them using their links. Disclaimer- I have no affiliation with the group nor am I being financially compensated for this shoutout. All reader shoutouts are just done to share what the community is working on, with no other strings attached.
If you’re doing interesting work and would like to be featured in the spotlight section, just drop your introduction in the comments/by reaching out to me. There are no rules- you could talk about a paper you’ve written, an interesting project you’ve worked on, some personal challenge you’re working on, your content platform, or anything else you consider important. The goal is to get to know you better, and possibly connect you with interesting people in the community. No costs/obligations attached.
Been fairly busy this week so not too many videos or articles to talk about. I am exploring a new technology and skillset, so expect to see more soon.
I’ll catch y’all with more of these next week. In the meanwhile if you’d like to find me, here are my social links-
Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819

