Meta-Learning: Why it’s a big deal, it’s future for foundation models, and how to improve it
How Meta Learning might be the future for creating better foundation models
Ever since BERT and other large deep-learning models started becoming accessible to the mainstream, we’ve seen more and more companies shift to utilizing these large proven ‘foundation models’ as a base for their techniques. By utilizing pre-trained models, you can get a headstart in creating the perfect model for your use. This has been accelerated by the development of techniques- such as: Transfer Learning, Fine Tuning, Model Distillation/Compression, and Multi-Task Learning- which allow us to tailor the brute power of pre-trained models to our bespoke needs.
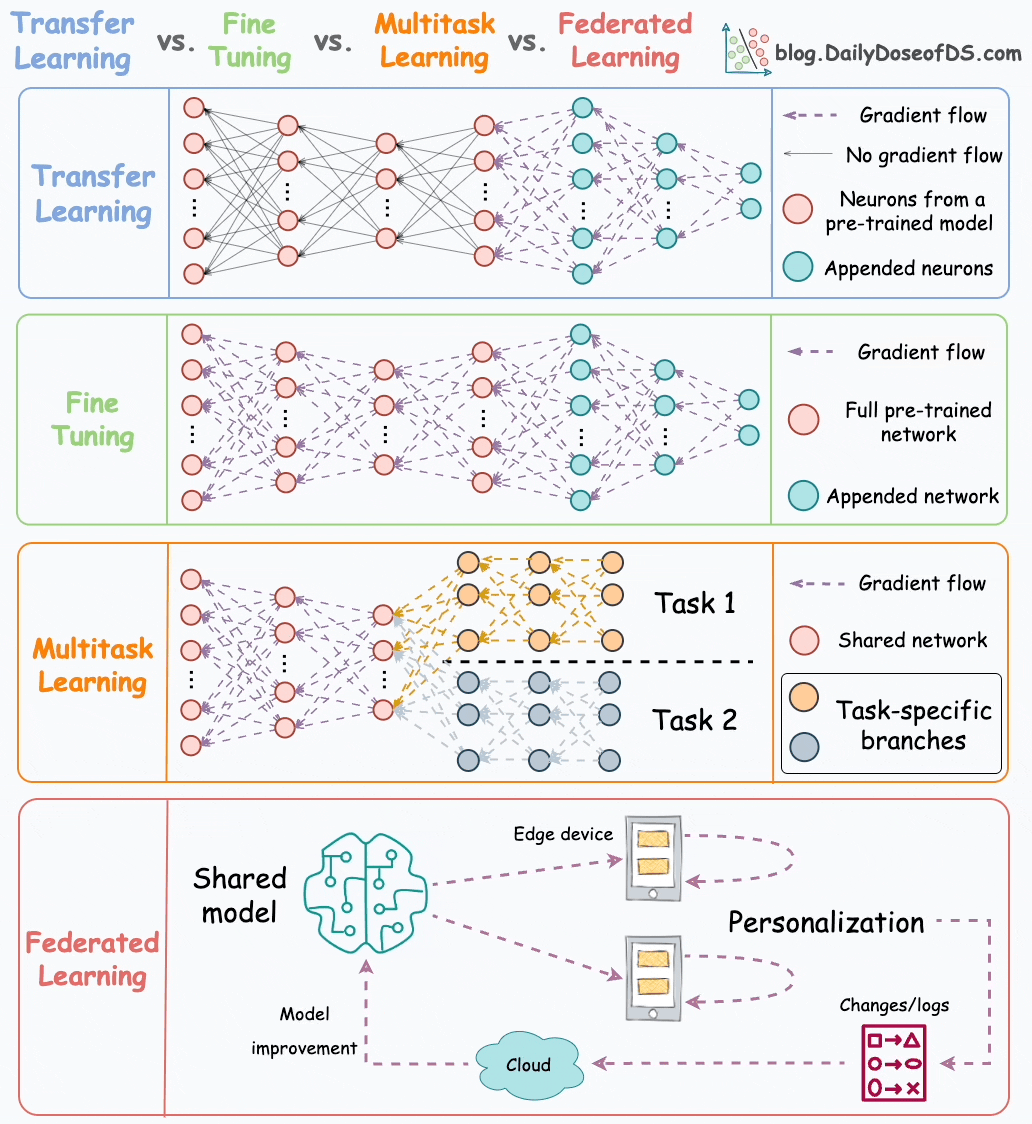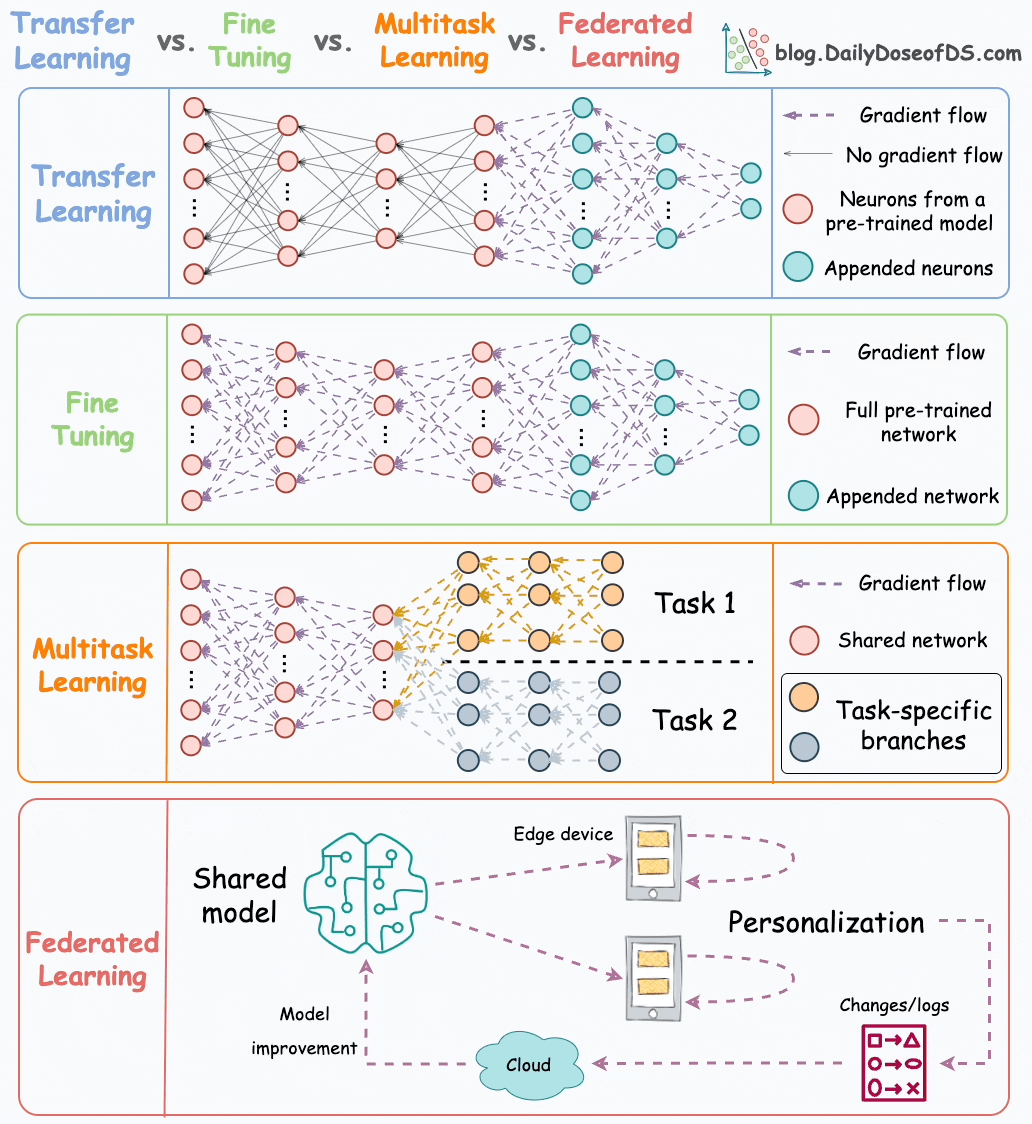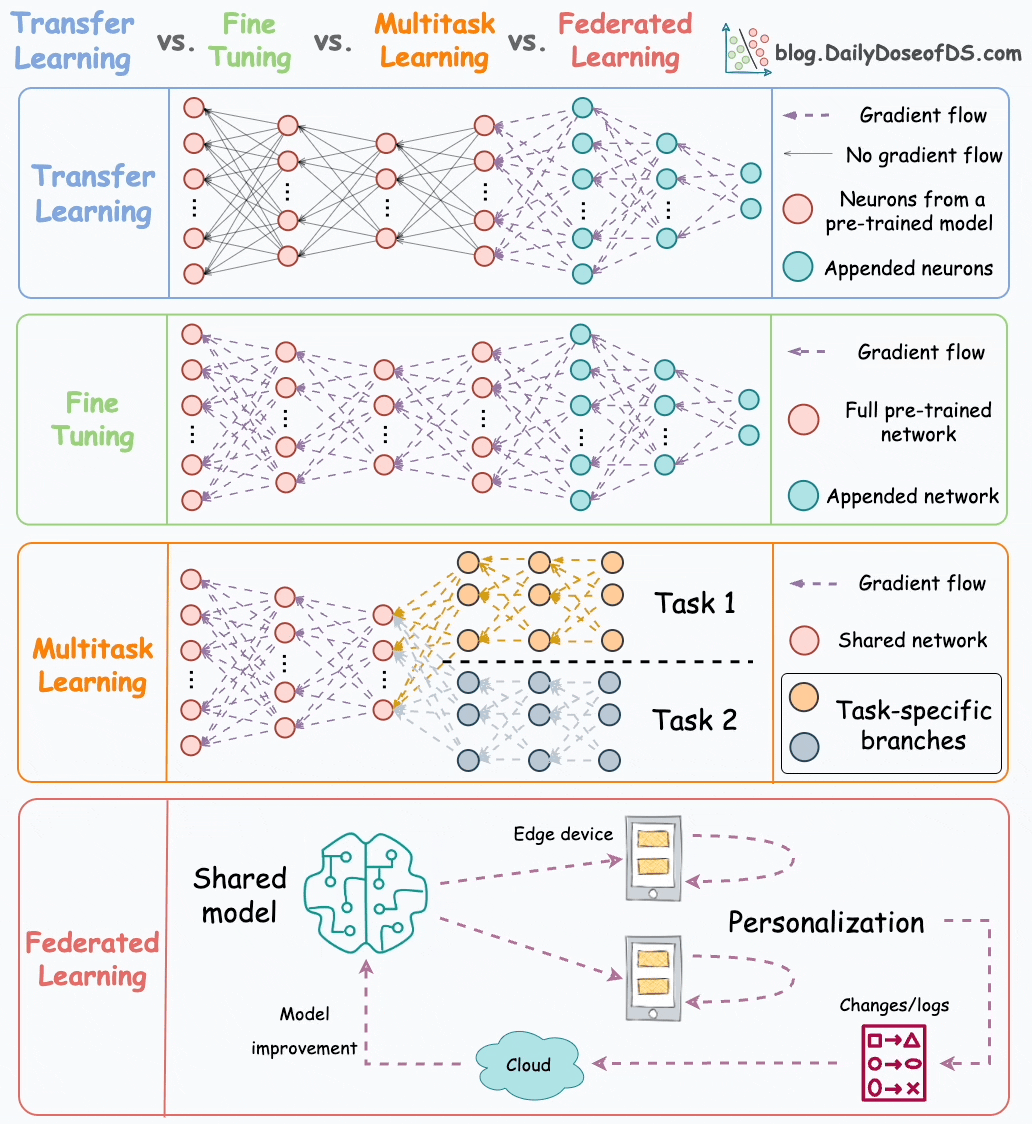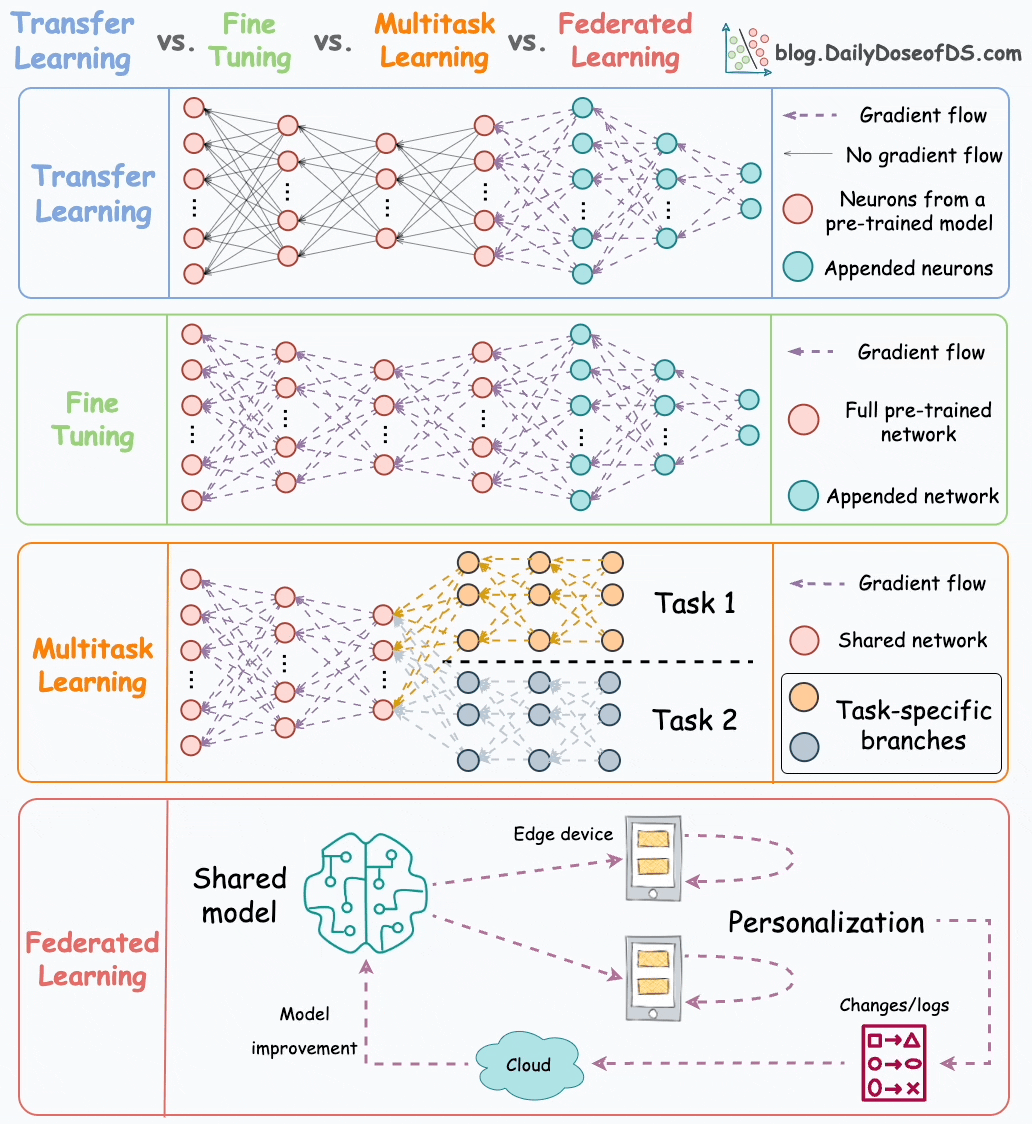
However, there is one problem here. So far, we don’t really have too many great ways to train the foundation models themselves. In a world where the above techniques are becoming more mainstream, and tasks like Retrieval-Augmented Generation are taking center stage, this is critical. While models like GPT are powerful, it is clear that we’re hitting the limits of traditional AutoRegressive LLMs. Neural Architecture Search has been struggling, model tuning doesn’t do much at the scale of these models, and it’s clear that there are serious diminishing returns in mindlessly scaling up.
We need another paradigm. Sam Altman admitted to something similar in a recent interview-
Large language models alone are unlikely to lead to AGI, says Sam Altman. Finding the solution is the next challenge for OpenAI.
The Open AI Developer Day presentation was a clear demonstration of this. When evaluated critically, Open AI didn’t really introduce anything new, as much as they just packaged up existing offerings to make things easier. In my assessment, this was done to improve revenue streams for OpenAI as they (and the rest of AI) try to figure out their next breakthrough.
In this article I will go over the following-
- What is Meta-Learning?
- How can Meta Learning be leveraged to create better foundation models?
- The limitation of Meta-Learning and analysis of the excellent paper,
“Population-Based Evolution Optimizes a Meta-Learning Objective” in how we can improve Meta-Learning.
Sound like a good time? Let’s get right into it-
We argue that population-based evolutionary systems with non-static fitness landscapes naturally bias towards high-evolvability genomes, and therefore optimize for populations with strong learning ability. We demonstrate this claim with a simple evolutionary algorithm, Population-Based Meta Learning (PBML), that consistently discovers genomes which display higher rates of improvement over generations, and can rapidly adapt to solve sparse fitness and robotic control tasks.
Join 150K+ tech leaders and get insights on the most important ideas in AI straight to your inbox through my free newsletter- AI Made Simple
What is Meta-Learning?
In layman’s terms, Meta-Learning refers to creating Machine Learning Agents that learn how to learn. This is typically achieved by training smaller ML models on specific tasks and then feeding the output of these models to our meta-learning model. The basic idea is expressed by the image below-
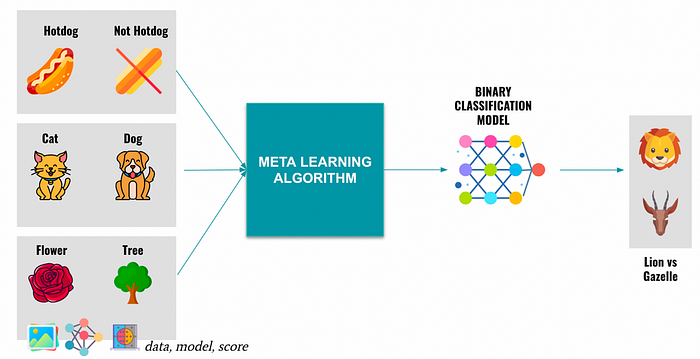
The core hope behind Meta-Learning is that tasks of a similar nature have similar underlying properties. By coming across enough (and diverse) tasks of a certain type (binary classification as shown above), we will be able to develop a model that has mastered that type. The next time we have a tricky binary classification challenge, we can use a binary classification foundational model to boost the performance. This process can be expensive to run (and won’t match the ROI of training on individual tasks). So, let’s talk about the advantages that meta-learning can bring.
Remember that the outcome of your ML model is heavily dependent on the distribution of your data. There are many cases in Machine Learning where your datasets are naturally extremely unbalanced. For example, I was once hired to work on Cancer Detection with a Medically Oriented University. Because Cancer is such a rare disease, the data collected will contain very few positive samples. If we trained our data on this example, then our model would be incentivized to just print no for every sample, regardless of whether the sample was actually negative.
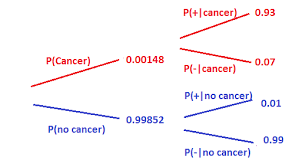
However, that is not all. Imagine cases in which gathering a lot of data is expensive or the data comes with a lot of regulations. In such cases, we typically use synthetic data, such as shown here by the authors of SinGAN-Seg. Meta-Learning could be a great alternative/supplement. Continuing with our medical theme, let’s take the example from the SinGAN-Seg paper. Imagine we wanted to classify an outgrowth as potentially dangerous based on medical images. Since Medical Data is expensive to annotate, hard to get, and has a lot of regulation, training our model with a lot of data would not be feasible. Instead, we can create a binary classification Meta-Learner to first get good at Computer Vision Classification, and then let our model learn this specific task.
Meta-learning is showing promise in recent genomic studies in oncology. Meta-learning can facilitate transfer learning and reduce the amount of data that is needed in a target domain by transferring knowledge from abundant genomic data in different source domains enabling the use of AI in data scarce scenarios.
-Source, “Meta-learning reduces the amount of data needed to build AI models in oncology”
Along with this, there are two overlooked advantages of Meta-Learning that make it particularly useful to training next-gen foundation models-
- It is inherently multi-modal. Nothing stops you from training Computer Vision Classifier, NLP, and Tabular Classifiers and training a Meta-Classifier with their insights.
- You can also (theoretically) train meta-learners to master a domain. Say you have a lot of biomarker data and how it can be used to detect risk towards disease. You can train a Meta-Learning model to be able to take a person’s biometrics and catch their susceptibility to diseases. This takes more effort to set up but can be done.
In essence, this is what makes Meta-Learning so exciting. It can add a lot of flexibility and allow us to tackle tricky situations by stacking solutions to easier problems. My personal prediction for the future of Foundation Models is that we will see a greater emphasis on models/embeddings trained on specific domains (law, finance, medicine, etc). This will increase performance on these more jargon-heavy fields while boosting efficiency (restricted domains will enable smaller models).

All of this sounds great. So why haven’t you heard about Meta Learning yet? As we have alluded to earlier, Meta-Learning can be an expensive solution. To start getting to acceptable “general” performance we need a lot of training. While we can be clever and implement techniques such as Transfer Learning into pipelines to reduce costs, Meta-Learning is still extremely expensive. The authors of the paper articulate this perfectly in their statement, “The inherent challenge in traditional meta-learning lies in its expensive inner loop — if learning is expensive, then learning to learn is orders of magnitude harder.”
Here the inner loop would refer to the training of one particular task (learning to classify cats and dogs). Training for one task is costly enough. When we layer multiple tasks, there is a degree of “information destruction” as the learnings from one task might overwrite another, making your life that much harder. So what do we do about it?
Traditional meta-learning methods, however, are often bottlenecked by expensive inner and outer loops, and optimization can be limited by gradient degradation. Rather, we would prefer to continuously train a model on new tasks, and have the model naturally improve its learning ability over time
This is where the paper we’re going to break down today comes in. By framing meta-learning as an evolutionary problem, we can bypass some of these costs- “…thus there is demand for algorithms that discover strong learners without explicitly searching for them. We draw parallels to the study of evolvable genomes in evolutionary systems — genomes with a strong capacity to adapt — and propose that meta-learning and adaptive evolvability optimize for the same objective: high performance after a set of learning iterations.”
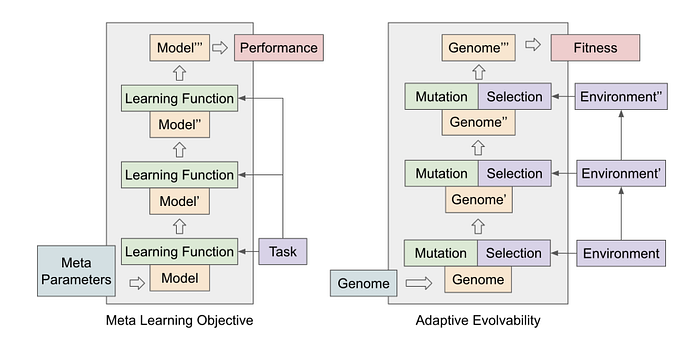
Let’s look into this with more detail.
Fixing Meta Learnings Cost Problem with Evolution
To understand the solution proposed, let’s hammer home why drawing parallels to evolutionary algorithms makes a lot of sense here-
From a meta-learning perspective, the ability for offspring to adapt to new challenges — which we refer to as adaptive evolvability– is of particular interest. Consider a shifting environment in which genomes must repeatedly adapt to maintain high fitness levels. A genome with high adaptive evolvability would more easily produce offspring that explore towards high-fitness areas
As I’ve covered in my article- Why you should implement Evolutionary Algorithms in your Machine Learning Projects- EAs are great for cost-effective results, especially through large search spaces. Combine this with the fact that EAs create solutions with evolvability, and we can see why Evolutionary Algorithms are ideal for the Meta-Learning context. We have seen some interesting work in this space, but the authors of this paper went a step beyond. Let’s analyze their algorithm next.
The algorithm used to improve Meta-Learning
To make Evolutionary Genomes that are great for Meta-Learning, we put a very heavy premium on the genomes that show an ability to adapt. The authors also add a twist to their learner.
Meta-Learning is typically designed in layers. The lower levels (the inner loops) focus on task-specific learning (cats vs dogs) while the higher levels (outer loops) focus on generalizing to domains (classification). Since Evolutionary Algorithms don’t need a gradient, they have been used in the outer loop. For this algorithm, EAs are used in both the outer loop and the inner loop creating genomes that evolve, “while it improves its own learning ability”.

Looking at the algorithm, you might be wondering what their differentiator is. After all, many EA-based systems have similar core algorithms (which is one of the reasons I love them). What differentiates this team, and the results is a simple idea. In a sentence, “The key intuition behind PBML is that evolutionary systems with large populations naturally optimize for long-term fitness”. This is implemented in many ways. PBML starts off with a very high initial population, which allows for greater search space exploration. Higher population sizes reduce noise and are better for actually understanding the effects of selection (higher sample size →lower variance in results).
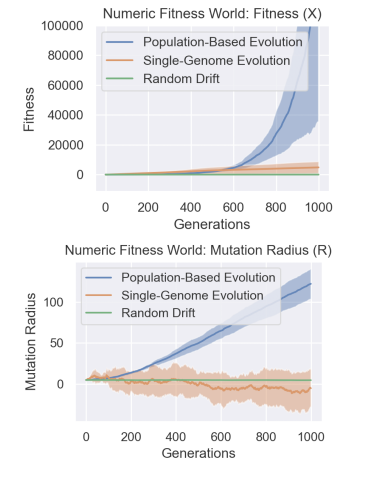
It’s important to also note that in this algorithm, weaker genomes are allowed to reproduce. In traditional EAs, the strongest genome is the one that spawns offspring. The search-space exploration happens mostly through mutations. This is great for getting solutions to one specific task in a cost-effective manner. However, when it comes to Meta-Learning, and generalizing to larger tasks, this approach doesn’t work too well. As the above graph shows using only a Single Genome isn’t too much better than Random Drift for long-term learning. Contrast this with PBML, which clearly stands out. This is something I first discovered on accident in 2018, and has been a key learning ever since.
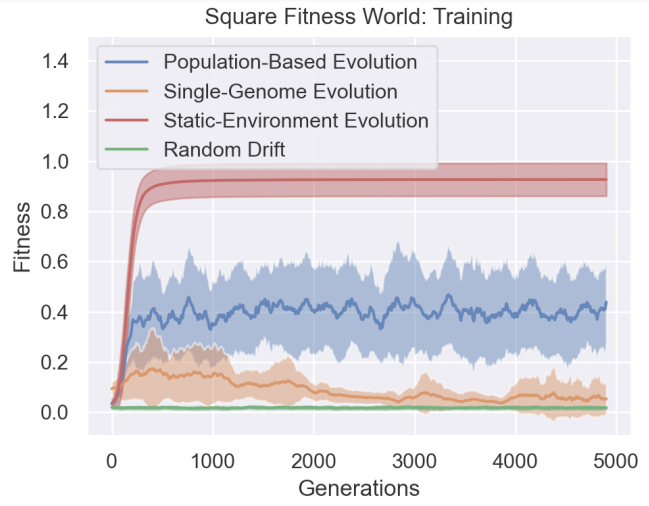
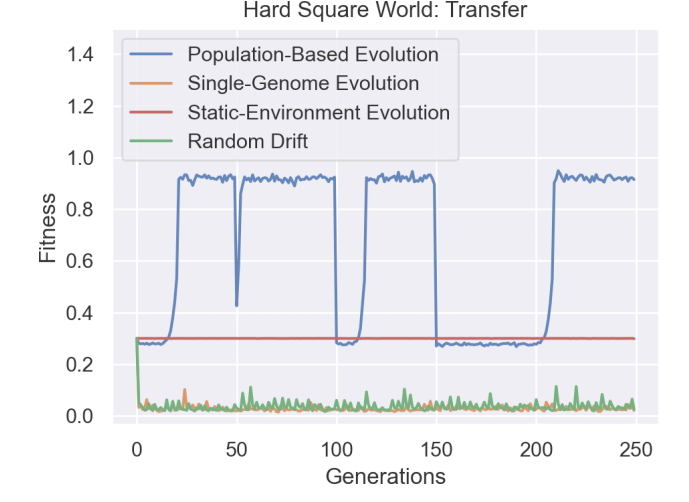
When the researchers transfer Genomes trained in one environment into another, PMBL genomes find higher-performing mutations when compared to the other protocols. And when we compare it to static environment genomes, PBML prioritizes evolution a lot more. This is very encouraging.
In evolutionary systems, genomes compete with each other to survive by increasing their fitness over generations. It is important that genomes with lower fitness are not immediately removed, so that competition for long-term fitness can emerge. Imagine a greedy evolutionary system where only a single high-fitness genome survives through each generation. Even if that genome’s mutation function had a high lethality rate, it would still remain. In comparison,in an evolutionary system where multiple lineages can survive, a genome with lower fitness but stronger learning ability can survive long enough for benefits to show
-One of the biggest mistakes that AI Teams often make is to blindly run after optimizing for performance on metrics w/o considering long-term consequences.
Figure 3 helps us check off the most important aspect of a genome for Meta-Learning- an ability to generalize to new and unseen tasks. This was the part that excited me the most and prompted this article. However, when it comes to more complex tasks, the performance of PBML drops slightly. This is because of an implicit bias in the algorithm. While PBML does encourage search space exploration a lot more than traditional methods, it still implicitly constraints the mutations to the more high-performing but safer configurations. This means that in cases where the true optimal lies beyond what would be normal, PBML would stop at a fit but suboptimal mutation. This can be seen in the table below when PBML creates solutions with the best average fitness but not the top performer.
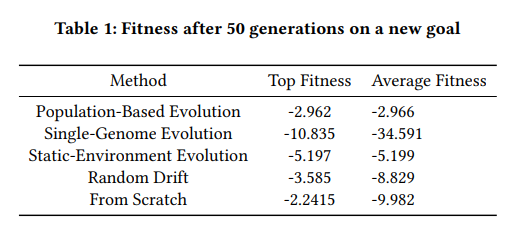
The authors state this problem perfectly in the following paragraph-
Notably, the population-based and static-environment genomes learn to constrain their mutation functions, and can maintain strong policies through many generations. In contrast, offspring from genomes in the other methods have a high chance to mutate badly, lowering their average fitness. This constraint, however, comes at a slight cost. The population-based genome comes close to the top-performing policy but falls short, as it likely has stopped mutation in a module that is slightly sub-optimal. This can be seen as a exploration-exploitation tradeoff, in which the genome gains a higher average fitness by constraining its search space of offspring, but can fail when the optimal solution is outside the space it considers.
One possible way to counter this would be to occasionally give passes to a few “fatal” solutions in simulation. This would allow the search space exploration to go into completely different configurations and might allow us to find powerful solutions that are surrounded by low-fitness configurations. This is similar to how the authors of Sparse Weight Activation Training would bring back pruned neurons and connections to explore a greater set of topologies.
If you’re a huge fan of Attack on Titan, another approach is to have a set of “scout genomes”. The purpose of these scouts is to die in exploration, in hopes of finding new viable spaces for growth (just like the Scout Regiment from AoT).
Both are something I’ve worked on in the past and have delivered great results. If you would like to know more, reach out using my social media links and we can set something up.
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow.
If you find AI Made Simple useful and would like to support my writing- please consider becoming a premium member of my cult by subscribing below. Subscribing gives you access to a lot more content and enables me to continue writing. This will cost you 400 INR (5 USD) monthly or 4000 INR (50 USD) per year and comes with a 60-day, complete refund policy. Understand the newest developments and develop your understanding of the most important ideas, all for the price of a cup of coffee.

Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819
