What I Learned From Thinking Fast And Slow
Quite possibly the single most important book ever written for data scientists, decision makers, and everyone else.
In case you missed it, Nobel Laureate (Economics) Daniel Kahnemann passed away recently. Kahnemann was best known for his research into human decision-making and the various flaws/biases that influence our decision-making processes. His book, “Thinking Fast and Slow”, was perspective-changing for me. I do not use this lightly, and there are only two other books that I would say this about (Don Quixote and The Prince).
In this email/post, I want to convince you to give this exceptional book a read. Here are some highlights:
A Summary of the Book: Thinking Fast and Slow is about people and our decision making. It states that our minds operate using two distinct systems:
- System 1: Fast, automatic, intuitive, and emotional. This is the default system our brain runs on.
- System 2: Slow, effortful, logical, and deliberate. We have to intentionally activate this system. It takes a lot of effort, so we can’t use this as a default. Furthermore, System 1 can often skew the analysis done by System 2 (for eg. take confirmation bias: our analysis (S2) will often build a narrative from cherry-picked examples that suit our original conceptions/gut feelings (S1) ). This is why being mindful of our biases is key to making better decisions- this helps us counteract some of the underlying pressure that System 1 exerts to skew our decisions.
The book covers (in a lot of depth) how this split impacts decision-making and the various cognitive biases that arise out of our architectural design.
Why you should read it: We live in a world fueled by rapid information, and instantaneous decisions. The sensory overload heightens the weaknesses of our System 1, and lulls us into automatic judgments and a lack of critical thinking. Thinking, Fast and Slow is an antidote. Studying the biases helped me step back, question our automatic responses, and make better choices (much of my writing has arisen from me stepping back and questioning whether the dominant narrative made sense to me). The book is also very very humbling.
How to Read Thinking Fast and Slow: The book gets very deep into the experiments and their various implications. This makes it a drag to read, and it’s not a book made for reading over a day/weekend (unless you’re very interested in the experiment design itself). Instead, I’d recommend reading TFAS over months, where you come back to the book regularly to study the various biases and the experiments. I also had a lot of fun critiquing the setup of the experiments themselves, poking at the limitations, and thinking about how I would redesign them. The biggest benefit I got from the book was when I started looking into how various PR communications/marketing messages online try to exploit these biases to convince us to go with their messages.
Without this book, I’m sure I would have been a lot more vulnerable to getting caught up in the hype-based repetitive falsehoods that we often discuss in our cult. I want to spend the rest of this write-up talking about some of the most important realizations that Thiking Fast and Slow has helped me reach (both directly and indirectly).
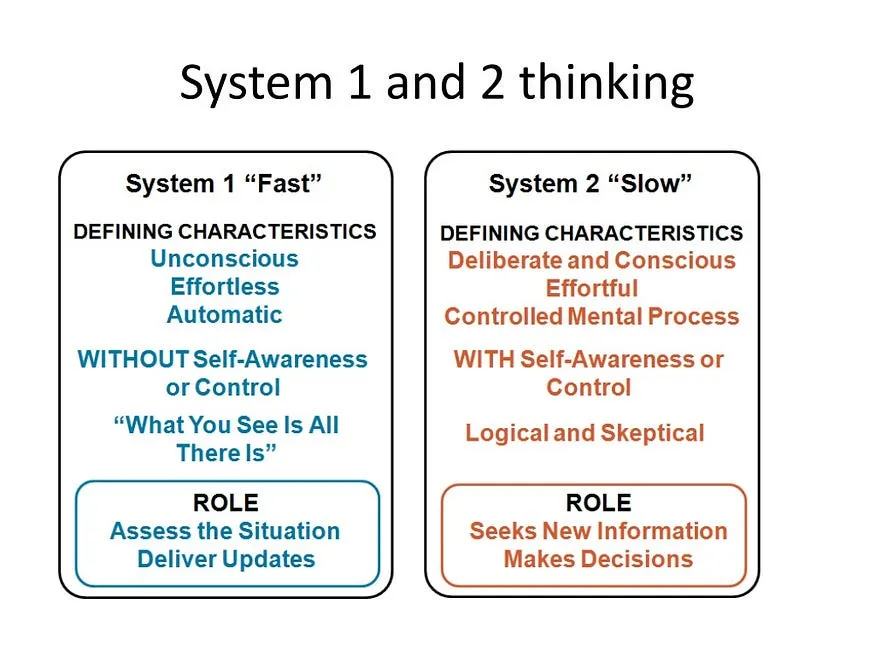
Systems 1 vs 2 and Understanding Biases
System 1 thinking is our default — fast, automatic, and effortless. It operates on intuition, emotions, and learned patterns. Here are some key characteristics of System 1:
- Fast and Automatic: System 1 processes information quickly and without much conscious effort. It’s the system that works with your reflexes or recognizes your favorite song playing somewhere in a public space. System 1 is always activated and helps you move through the world without being overwhelmed by sensory information. This is why so many ads and media communications rely on imagery and emotional anchoring: these get processed by System 1 before our critical thinking can kick in.
- Pattern Recognition: System 1 excels at identifying patterns and making quick judgments based on past experiences. It uses mental shortcuts called heuristics to navigate the world efficiently.
- Emotionally Driven: Emotions play a significant role in System 1 thinking. We often make impulsive decisions based on feelings like fear, anger, or excitement.
- Powerful: System 1 drives a majority of our thinking, and can exert influence on our System 2 thinking even when we don’t want it to. Kahnemann has various tests/trick questions that the reader can take throughout TFAS. I found myself falling for the various tricks, even when I knew the premise of this book and was expecting tricks. Many of these tricks relied on using anchors/frames to make my System 1 focus on certain pieces of information and discard others. This made my System 2 work on ‘Bad Data’ leading to false conclusions.
System 2: The Slow and Deliberative Thinker
System 2 is the more deliberate and energy-consuming way of thinking. Here’s what sets System 2 apart:
- Slow and Calculated: System 2 takes time and mental effort to activate. It’s used for complex calculations, critical thinking, and problem-solving.
- Logic and Reason: System 2 relies on logic and reason to analyze information and make decisions. It’s the system we use to solve math problems or weigh different options before making a choice.
- Limited Capacity: System 2 has limited resources and can easily get overloaded. This is why we tend to rely more on System 1 for most daily tasks (this is a good thing).
The way these two systems interact determines how we think.
How Cognitive Biases Shape the Interactions in our Systems
While these systems work together, System 1 often takes the lead. It’s efficient and keeps our brains from being constantly bogged down by analysis paralysis. This is accomplished by the use of Cognitive Biases. While biases are often treated like a dirty word, they are a value-neutral phenomenon. From an information theory perspective, a bias is simply a shortcut used by a decision-making model (whether our brains or an AI) uses to prioritize and work with information. This can be positive (not eating something b/c it smells funny), value-neutral (my love for chocolate milk), or negative (racial biases). The big difference between human and AI biases is simply where it comes from: human bias is architectural while AI bias tells us something deeper about our data.

In AI terms, System 1 is a simple checker, while System 2 is a much more powerful Deep Learning model. However, it the role of System 1 extends beyond that. In most cases, System 1 also acts like our feature extractor/Data Pipeline, directly feeding the input that goes into System 2. Here are 2 major ways how:
- Confirmation Bias: System 1 confirmation bias reinforces our existing beliefs by seeking out information that confirms them and ignoring information that contradicts them. This creates a skewed perception of reality.
- Framing Effects: The way information is presented (the “frame”) can influence our decisions even if the underlying facts remain the same. System 1 is more susceptible to framing effects, leading to choices influenced by the presentation rather than logic.
We could spend the entirety of human existence studying why you (yes, you specifically), your mom, and Manchester United’s Transfer Division are the holy trinity of making terrible decisions (Happy Easter to those who celebrate, btw). But that would involve watching too many clips of Anthony spinning around, so I’ll have to pass on that. Fortunately, risk experts like Filippo Marino have dedicated their lives to answering just that.
Our risk judgment is often clouded by an instinctual bias towards the dramatic and memorable. Terrorist attacks, for example, despite their relative rarity, loom large in our collective consciousness. This is a result of the ‘availability heuristic,’ a cognitive shortcut where we inflate the likelihood of events that are eye-catching and easily recalled, while we downplay or disregard the risks associated with more common but statistically more hazardous situations.
Similarly, our judgment is frequently skewed by ‘base rate neglect’ — a tendency to ignore broad statistical information and instead focus on specific, anecdotal accounts. With this bias, our recent experience visiting a foreign city, for instance, can feel more significant than (more predictive) violent crime or road accident rates.
In each of these instances, our instinctive risk assessment falls short, underscoring the need for decision-making processes that incorporate sound data and rational analysis.
- Beyond Instinct, by Filippo Marino. The Safe-Esteem substack is a goldmine to help you understand cognitive biases and how they often mess with our risk judgements.
With that out of the way, let’s talk about some of the most powerful ideas discussed in Thinking Fast and Slow.
Biases, Phenomena, and Frames
Reversion to the Mean
Reversion to the mean describes the statistical tendency for extreme results or events to be followed by less extreme results until things converge back to the average. It sounds incredibly obvious, but appreciating its implications is key for any decision-maker (especially for those who work with data).
Why does it happen?
Several factors contribute to reversion to the mean:
- Random Variation: Any outcome is influenced by chance. An exceptional result may simply be due to a string of good luck/external factors that’s unlikely to repeat itself.
- Measurement Error: Tests and measurements aren’t perfect. Unusually high or low scores may partly be influenced by measurement error, leading to more average results later.
- Underlying Stability: Most systems have a natural average or equilibrium they tend to gravitate towards. Deviations from this average will often correct over time.
Why it Matters
Understanding reversion to the mean is crucial to avoid bad reasoning in various areas:
- Misinterpreting Performance: We need to be careful not to overestimate the impact of one extreme performance, positive or negative. Reversion to the mean suggests that it might be partially fluke, not a true reflection of permanent change.
- Evaluating Interventions: If we make a change (like starting a new training program for employees) and then observe an extreme improvement, it’s tempting to attribute the change solely to the intervention. However, reversion to the mean could also be at play, and we need to take that into account to properly assess results.
- Predicting the Future: Reversion to the mean suggests that extrapolating too far from recent extreme results is often misleading. Future outcomes are likely to be less extreme. This why it is crucial to improve your data sampling and understand the underlying domain, since both help us evaluate whether a particular set of prior data is a good model for predicting the future.
I took a long time to appreciate this one, but now I see it everywhere (including the numbers in my writing).
Loss Aversion
Something that changed the way I saw risk-taking was Kahenmann’s study on Loss Aversion. Our drive to avoid a loss is 2.5x stronger than our drive to pursue wins of similar magnitude.

This might’ve risen from an evolutionary context (in the jungle, taking too many risks can lead to death, and the conservative people are the ones that survive). We’ve inherited this, even when it’s not fully suited for the modern world.
Understanding Loss Aversion has freed me in a way, and helped me be more experimentative in what I do, both personally and professionally.
Anchoring Bias:
We have a tendency to become overly fixated on the first piece of information offered (the “anchor”). This is a technique used in salary negotiations to low-ball prospective employees during salary negotiations. The converse is also used by organizations trying to sell us something.

Two things especially blew my mind about the anchoring effect. Firstly, turns out that we can use completely irrelevant things as anchors. This is done very subtly, so being on the lookout for this nudge is key. Secondly, the anchoring bias might worsen the impact of the automation bias (our tendency of accept the results from an automated decision making system more less critically).
The responses we get from AI machine learning models can potentially trigger the anchoring bias and thus affect decision-making. A response provided by an AI tool may cause individuals to formulate skewed perceptions, anchoring to the first answer they are given. This allows us to disregard other potential solutions and limits us in our decision-making.
After being exposed to an initial piece of information, feeling short on time and being preoccupied with many tasks is thought to contribute to insufficient adjustments. But this can be avoided by taking the time and effort to avoid jumping to conclusions. A study by Rastogi and colleagues found that when people took more time to think through the answers provided by the AI, they moved further away from the anchor, decreasing the effect on their decision-making.
Framing Effects:
The way information is presented (the “frame”) dramatically influences how we perceive it and the decisions we make. Once again, this has some interesting implications when looking at communications and how they attempt to subtly manipulate perceptions.
In a study among undergraduate students, respondents were presented with the following medical decision-making problem, described with both a positive and a negative frame. Responses were recorded on a 6-point Likert scale ranging from 1 (very bad) to 6 (very good).
Positive: 100 patients took the medicine, and 70 patients got better. How would you evaluate the drug’s effect?
Negative: 100 patients took the medicine, and 30 patients didn’t get better. How would you evaluate the drug’s effect?
The results revealed that the framing influenced the evaluation: when the drug’s effect was described with a loss frame (30 patients didn’t get better), respondents gave negative evaluations. When the effect was described with a gain frame (70 patients got better), respondents gave positive evaluations.
Many AI Researchers and Marketers understand this very well, and deliberately name their benchmarks/technologies to nudge towards favorable decisions.
Take the benchmark TruthfulQA for example. Due to its name People utilize it as a test for alignment, unaware of various limitations.Researcher and Youtuber Yannic Kilcher had a fantastic demonstration on its weakness when he fine-tuned an LLM on 4-Chan data and showed that it was the best performer on this benchmark. However, certain sections of the AI Safety crowd got triggered by this, and this led to a massively one-sided coverage of the whole fiasco. Yannic’s bot was framed as a “hate-speech machine”. Ultimately this controversy led to HuggingFace gating this model (the problems w/ TruthfulQA that this model demonstrated have never been solved to my knowledge).
FYI: Looking at all the strawmen that the AI Safety/Ethics people created, their constant refusal to engage in good faith discussions, and the spinelessness of AI Academia to call said Ethics folk out on their egregious behavior was one of the biggest reasons I decided not to do a Ph.D. or pursue Professorship (I only started writing to help with my journey into academia).
Once again, one need only look at the communications by AI Doomers to find countless examples where AI is portrayed as a risk similar to nuclear war, pandemics, or climate change. This framing is used to draw out a visceral fear, so that people are more likely to agree with the Doomer. Any agenda-heavy communication will invariably use various types framing of manipulate consumer opinion.
Availability Heuristic:
“Repeat a lie often enough and it becomes the truth”
-Goebbels
We assess the likelihood or frequency of an event by how easily examples come to mind and not by their true base rate. This frequently leads to misjudging true probabilities.
Availability Heuristic is particularly nasty when combined with social media. Social Media by it’s very nature tends to push up the most extreme kinds of content/creators. People that spend a lot of time online can make the mistake of conflating these anomalies with the ‘normal’, and thus feel bad about themselves by comparison. Financial Scammers often prey upon this by constantly bombarding financially illiterate people with constant ads and images of lifestyles, to confuse their marks and ultimately scam into them buying their products/investments.
Because these people often use their social proof to sell their products. They rely on massive ad campaigns, where they pay a lot of celebrities, outlets, and other influencers, to promote their products. Regular Folks following these people/organizations come across these promotions and google the original product. There, they see the paid releases + massive following and think this product is legit. So now real people put real money into this project, which further increases the hype behind this, forming a strong feedback loop.
- SBF is a fraud. But he was never the problem
The crazy about this heuristic is that it doesn’t even have to be true. AI Hype Merchants (both positive and negative) have been using this tactic to build their profiles, scare millions, and sell their cures to problems that no one is having. The key is to create an echo chamber where the same message is repeated all the time. Most people don’t have the cognitive bandwidth to take a step back and start evaluating these claims (especially when stated by ‘experts’).
These experts also often combine this with ‘false consensus’ and social proof to avoid intellectual critiques.

When it comes to the internet, and soo many social media debates, this is probably one of the most important swerves that you should be on the lookout for.
Let’s talk about another bias that shows up often in AI discussions.
Representativeness Heuristic:
We make judgments about things or people based on how closely they resemble a typical example, sometimes ignoring statistical probabilities. “For example, if we see a person who is dressed in eccentric clothes and reading a poetry book, we might be more likely to think that they are a poet than an accountant. This is because the person’s appearance and behavior are more representative of the stereotype of a poet than an accountant.”
Many conversations about AGI often loop around this heuristic. Dr. Bill Lambos, computational biologist, had a very salient observation about LLMs and their usage of language: LLMs were exceptional at mimicking the behavior of human intelligence and language comprehension but did not display the underlying drivers of intelligence-
The answer is that AI programs seem more human-like. They interact with us through language and without assistance from other people. They can respond to us in ways that imitate human communication and cognition. It is therefore natural to assume the output of generative AI implies human intelligence. The truth, however, is that AI systems are capable only of mimicking human intelligence. By their nature, they lack definitional human attributes such as sentience, agency, meaning, or the appreciation of human intention.
-AI is Truly Brainless…
In his recent instant classic, Logan Thornloe expressed something similar about Devin, i.e- that a lot of the hype/fear about Devin replacing software engineers exists because many people don’t truly understand what a software engineer is supposed to do. Since Devin seems like it does the same things as a software engineer, people assume that is a replacement for one.
The supposed most techno-literate group of society has become the most fear-based regarding AI advancement. There are certain tasks AI is good at and they’ll replace those tasks within jobs first. This isn’t exclusive to software engineering. There are aspects of all jobs that will be automated soon and many more that will take a longer time for AI to do so. By the time software engineers are fully replaced, there are many other jobs that will already have been replaced. Why software engineers are the group panicking most about AI taking jobs, I will never understand.
The release of Devin has uncovered two things about most software engineers that are way more interesting to me than the autonomous engineer:
1.Most engineers have no idea what their job actual consists of and why they’re paid well.
2.Most engineers seriously lack an understanding of machine learning.
-Devin Has Exposed a Major Issue with Software Engineering
In both cases, we see this bias at play: AI does a particular task related to competency, so we assume that the AI displays the underlying competency. AI Doomers often utilize a similar fallacy when talking about how OS AI can be used to create biological weapons.
Keep this one in mind as you observe communications. You’ll see how often people utilize this to manipulate opinion in their favor.
Thinking Fast and Slow is a book I go back to every year, and each year it teaches me something new. Its dense material means that it has a lot of re-reading value since there’s always a nuance or an idea that I missed in previous interactions. It’s a book that will hook into your soul and permanently mold its texture into something different. It does what all great books/media do: takes you on a journey of self-discovery. If you haven’t had the opportunity to read it yet, now’s a good time. If you have read it already, let me know what your experience with the book was.
This is quite different from the usual pieces that I do. In case you’re itching for something more technical: check out my conversation with the amazing Sean Falconer. We dive deep into the world of prompt injection attacks in Large Language Models (LLMs). Our conversation covers LLM injection attacks, existing vulnerabilities, real-world examples, and the strategies attackers use. Got great feedback from the viewers, and I’m sure you’d enjoy it too.
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow.

I put a lot of effort into creating work that is informative, useful, and independent from undue influence. If you’d like to support my writing, please consider becoming a paid subscriber to this newsletter. Doing so helps me put more effort into writing/research, reach more people, and supports my crippling chocolate milk addiction. Help me democratize the most important ideas in AI Research and Engineering to over 100K readers weekly.
PS- We follow a “pay what you can” model, which allows you to support within your means. Check out this post for more details and to find a plan that works for you.
I regularly share mini-updates on what I read on the Microblogging sites X(https://twitter.com/Machine01776819), Threads(https://www.threads.net/@iseethings404), and TikTok(https://www.tiktok.com/@devansh_ai_made_simple)- so follow me there if you’re interested in keeping up with my learnings.
Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819
